


PDF를 마크다운으로 완벽하게 변환하는 법 IBM Docling 가이드
요즘 인공지능이나 대형 언어 모델을 활용하다 보면 PDF나 워드 혹은 파워포인트 같은 자료를 다루기가 참 까다롭다는 생각을 하게 되는데요.
단순하게 텍스트를 추출하는 것만으로는 원본의 레이아웃이 깨지거나 표와 제목 같은 문서의 핵심 구조가 유실되는 문제가 자주 발생합니다.
결국 모델의 성능을 제대로 끌어올리기 위해서는 단순히 문자열만 뽑아내는 것이 아니라 문서의 구조를 최대한 보존하는 전처리가 무엇보다 중요합니다.
이런 복잡한 고민을 해결하기 위해 나타난 구원투수가 바로 오늘 소개해 드릴 'Docling'이라는 도구입니다.
문서 구조의 파괴자 PDF를 길들이는 Docling
'Docling'은 IBM 리서치 취리히에서 개발하여 발표한 강력한 오픈소스 문서 변환 라이브러리인데요.
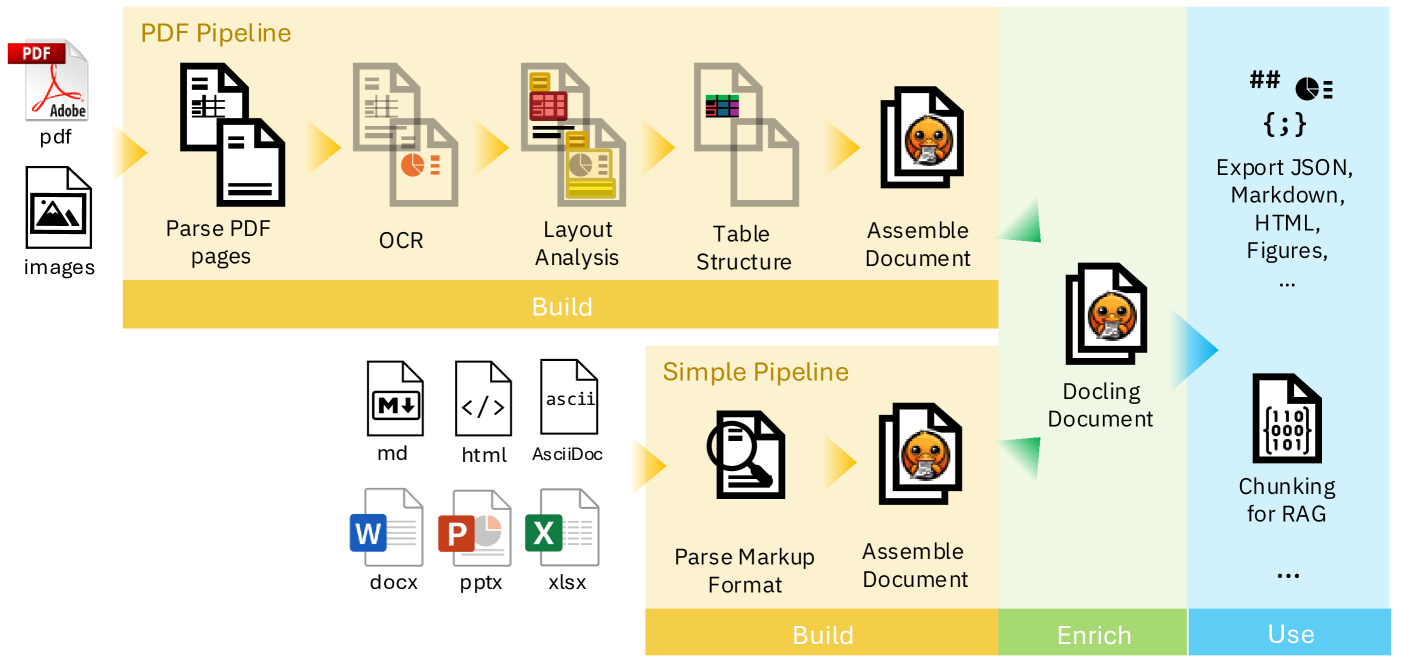
이 도구는 단순한 텍스트 추출기를 넘어 문서의 시각적 레이아웃과 의미론적인 뭉치를 정확하게 포착하는 능력을 갖추고 있습니다.
기존 도구들이 표의 선을 무시하거나 제목과 본문을 구분하지 못해 텍스트를 엉망으로 섞어놓는 것과 비교하면 정말 혁신적인 성능을 보여줍니다.
덕분에 우리는 PDF 속의 복잡한 표나 리스트 혹은 그림 같은 요소들을 마크다운이나 JSON 형식으로 아주 깔끔하게 바꿀 수 있습니다.
Docling 내부를 지탱하는 탄탄한 아키텍처
'Docling'의 내부 작동 원리를 살펴보면 입력되는 문서 형식에 따라 처리 방식을 유연하게 바꾸는 파이프라인 구조를 취하고 있는데요.
우선 PDF나 이미지 파일이 들어오면 레이아웃 분석과 광학 문자 인식 그리고 표 구조 인식 등을 통해 문서의 뼈대를 다시 구성합니다.
이러한 정교한 작업을 담당하는 것이 바로 'StandardPdfPipeline'이라는 핵심 엔진입니다.
반면에 이미 구조 정보를 담고 있는 오피스 문서나 HTML 혹은 아스키독 같은 형식은 정보를 최대한 활용하여 변환을 수행합니다.
이럴 때는 상대적으로 가벼운 'SimplePipeline'이 투입되어 효율적으로 데이터를 처리합니다.
결과적으로 어떤 문서가 들어와도 결국 'DoclingDocument'라는 공통 형식으로 통일되도록 설계되어 있습니다.
이렇게 통일된 데이터는 나중에 엑스포트하거나 덩어리로 나누어 검색 증강 생성 시스템에 통합할 때 엄청난 편의성을 제공합니다.
본격적으로 시작하는 Docling 설치와 환경 구성
기본적인 개념을 익혔으니 이제 내 컴퓨터에 'Docling'을 설치하고 직접 사용해 볼 준비를 해야 하는데요.
이 라이브러리는 파이프라인 기반으로 동작하기 때문에 기본적으로 파이썬 환경이 설치되어 있어야 합니다.
버전 관리를 위해서는 'mise' 같은 도구를 활용하는 것이 훨씬 깔끔한 작업 환경을 만드는 데 도움이 됩니다.
준비가 되었다면 터미널을 열고 'pip install docling' 명령어를 입력하여 패키지를 설치해 주시면 됩니다.
명령어 한 줄로 끝내는 CLI 사용법
설치가 끝났다면 이제 'docling'이라는 명령어를 통해 곧바로 파일 변환을 시도해 볼 수 있는데요.
가장 기본적인 사용법은 'docling' 뒤에 변환하고 싶은 PDF 파일 경로를 적어주는 방식입니다.
명령어를 실행하면 동일한 디렉토리에 원본 문서 구조를 그대로 반영한 마크다운 파일이 생성됩니다.
만약 결과물을 마크다운이 아닌 다른 형식으로 받고 싶다면 옵션을 활용하면 되거든요.
'--to json' 옵션을 추가하면 문서의 메타데이터와 구조 정보가 상세히 담긴 JSON 파일을 얻을 수 있습니다.
도움말이 궁금할 때는 '--help' 옵션을 입력하여 사용 가능한 모든 명령과 옵션을 확인할 수 있습니다.
여러 파일을 한꺼번에 처리해야 할 때는 와일드카드 문자를 사용하여 일괄 변환을 수행하는 것도 가능합니다.
놀라운 점은 로컬 파일뿐만 아니라 인터넷에 있는 PDF 주소를 직접 입력해도 알아서 내려받아 변환해 준다는 사실입니다.
동작이 제대로 되지 않거나 내부 과정을 확인하고 싶을 때는 '--verbose' 옵션을 통해 상세 로그를 출력해 보면 됩니다.
특수하게 OCR 엔진을 바꾸고 싶을 때는 '--ocr-engine' 옵션을 써서 테서랙트 같은 외부 엔진을 지정할 수도 있습니다.
개발자를 위한 파이썬 스크립트 활용 가이드
단순 명령어를 넘어 서비스에 통합하고 싶다면 파이썬 코드로 직접 구현하는 방식이 훨씬 강력한데요.
우선 'docling.document_converter'에서 'DocumentConverter' 클래스를 불러와야 합니다.
변환기 객체를 생성한 뒤에 변환하고 싶은 소스 경로를 넣고 실행하면 결과 객체를 받게 됩니다.
이후 'export_to_markdown' 함수를 호출하면 우리가 원하는 마크다운 문자열이 바로 튀어나옵니다.
이 과정을 통해 수백 장의 문서를 자동화된 파이프라인 안에서 손쉽게 처리할 수 있습니다.
AI가 보강하는 Docling의 실전 활용 전략
여기까지가 기본적인 사용법이었다면 이제는 실전에서 'Docling'을 어떻게 더 똑똑하게 쓸 수 있을지 고민해 봐야 하는데요.
특히 최근 유행하는 'RAG' 즉 검색 증강 생성 시스템에서 이 도구의 진가가 제대로 발휘됩니다.
단순히 텍스트를 나누는 것이 아니라 제목 계층을 기준으로 의미 있는 단위로 문서를 쪼개는 작업이 가능해지거든요.
예를 들어 특정 섹션 아래에 있는 내용들을 하나의 맥락으로 묶어서 임베딩하면 검색 정확도가 놀라울 정도로 향상됩니다.
왜 마크다운이 LLM 전처리의 정답일까
우리가 왜 굳이 PDF를 마크다운으로 변환해서 인공지능에게 전달해야 하는지에 대해서도 생각해 볼 필요가 있는데요.
마크다운은 텍스트 기반이면서도 구조를 명확하게 표현할 수 있는 아주 효율적인 형식이거든요.
인공지능 모델들은 샵 기호로 표시된 제목이나 대괄호로 감싸진 표 구조를 아주 잘 이해합니다.
불필요한 바이너리 데이터나 서식 정보를 제거하고 순수한 지식의 뼈대만 전달할 수 있다는 것이 가장 큰 장점입니다.
기존 도구들과 비교했을 때 Docling이 가지는 우위
기존에는 'PyMuPDF'나 'PDFPlumber' 같은 라이브러리들을 많이 사용해 왔던 것이 사실인데요.
하지만 이런 도구들은 표 안에 들어있는 글자들이나 여러 열로 나누어진 레이아웃을 해석하는 데 한계가 뚜렷했습니다.
반면에 'Docling'은 딥러닝 기반의 레이아웃 분석 기술을 탑재하여 문서의 시각적 맥락을 인간처럼 파악합니다.
특히 복잡하게 꼬여있는 표 구조를 인식하는 능력은 현재 오픈소스 생태계에서 최상위권에 속한다고 볼 수 있습니다.
고급 사용자를 위한 OCR 엔진 최적화 팁
문서가 깨끗한 디지털 파일이 아니라 스캔된 이미지라면 OCR 성능이 결과물의 질을 결정하게 되는데요.
'Docling'은 기본적으로 강력한 엔진을 내장하고 있지만 상황에 따라 최적화가 필요할 때가 있습니다.
한글이 섞인 문서를 다룰 때는 테서랙트의 한글 언어 데이터를 추가로 설치하고 엔진을 설정해 주는 것이 좋습니다.
또한 이미지의 해상도가 너무 낮다면 전처리 단계에서 명암비를 조절하는 작업이 수반되어야 더 정확한 결과물을 얻을 수 있습니다.
실제 변환 사례를 통해 본 Docling의 위력
실제로 아카이브에 올라온 복잡한 수식과 표가 가득한 논문을 하나 골라 변환을 시도해 보았는데요.
기존의 다른 도구들은 수식을 텍스트 조각으로 흩트려놓거나 표의 행과 열을 뒤섞어버리는 실수를 저질렀습니다.
하지만 'Docling'은 논문의 초록부터 결론까지 제목의 깊이를 정확히 인식하며 자연스러운 마크다운 파일을 생성해 냈습니다.
물론 모든 문서가 완벽하게 변환되는 것은 아니지만 현재로서는 가장 믿음직한 결과물을 보여준다고 확신합니다.
더 나은 문서 처리를 위한 끊임없는 고민
문서 전처리는 언뜻 보면 지루하고 단순한 작업처럼 느껴질 수도 있지만 사실 인공지능의 지능을 결정하는 핵심 공정인데요.
아무리 좋은 모델을 쓴다고 해도 입력되는 데이터가 쓰레기라면 결국 쓰레기가 나오는 결과가 반복될 뿐입니다.
모델을 튜닝하고 최적화하기 전에 우리가 가진 지식 자산인 문서의 형태를 먼저 정돈해 보시길 권장합니다.
'Docling'은 여러분의 그런 노력을 든든하게 받쳐줄 가장 강력한 도구가 되어 줄 것입니다.
앞으로 더 발전할 이 도구를 눈여겨보면서 여러분의 인공지능 서비스 품질을 한 단계 더 업그레이드해 보시길 바랍니다.
'Python' 카테고리의 다른 글
| AI 개발자를 위한 최강의 조합 FastAPI와 htmx 완벽 가이드 (0) | 2025.12.14 |
|---|---|
| 파이썬 개발, '제대로' 하고 싶다면 이 조합으로 시작하세요 uv, Ruff, Pyright (0) | 2025.09.07 |
| 구글 최신 AI 제미나이 2.5 플래시 이미지 API 공짜로 쓰는 법 (0) | 2025.09.07 |
| 파이썬 중첩 데이터 구조 완벽 가이드 현실 세계의 데이터를 다루는 기술 (0) | 2025.07.16 |
| 파이썬(Python) 최강의 기술, 데코레이터(Decorator) 완전 정복 (0) | 2025.05.17 |