


웹 개발자 필수 지식! HTTP 프로토콜의 역사와 작동 원리 파헤치기

인터넷 세상에서 HTTP (에이치티티피) 프로토콜은 정말 중요한 기본 약속 같은 건데요.
특히 웹 개발 분야에서는 모르면 안 될 필수 지식입니다.
최근에는 HTTP/2 (에이치티티피 투) 버전이 많은 관심을 받으면서 기술적인 뜨거운 감자로 떠올랐는데요.
이번 글에서는 HTTP (에이치티티피) 프로토콜이 어떻게 발전해왔고, 어떤 생각으로 설계되었는지 그 역사와 개념을 깊이 있게 다뤄보려고 합니다.
이 글을 통해 독자 여러분들이 이 중요한 기술을 확실하게 이해하는 데 도움이 되었으면 좋겠습니다.
1. HTTP/0.9: 인터넷 통신의 아주 초기 모습 알아볼까요?
HTTP (에이치티티피)는 TCP/IP (티시피아이피) 프로토콜을 기반으로 하는 응용 계층 프로토콜입니다.
이것은 클라이언트와 서버 사이의 통신 형식을 지정하는 데 초점을 맞추고, 데이터 패킷의 실제 전송 과정에는 관여하지 않습니다.
기본적으로는 80번 포트를 사용하는데요.
1991년에 나온 HTTP/0.9 (에이치티티피 영점구) 버전은 HTTP (에이치티티피) 프로토콜의 가장 초기 버전입니다.
그 구조는 아주 단순해서, GET (겟)이라는 명령어 하나만 가지고 있었습니다.
GET /index.html위 명령어의 의미는 TCP (티시피) 연결이 이루어진 후, 클라이언트가 서버에게 index.html (인덱스쩜에이치티엠엘) 웹 페이지를 요청한다는 것입니다.
이 프로토콜에 따르면, 서버는 오직 HTML (에이치티엠엘) 형식의 문자열로만 응답할 수 있었고, 다른 형식으로는 응답할 수 없었습니다.
예를 들면 다음과 같습니다.
<html>
<body>Hello World</body>
</html>서버는 전송을 마치자마자 바로 TCP (티시피) 연결을 끊어버렸습니다.
이 버전은 비록 단순했지만, 이후 HTTP (에이치티티피) 프로토콜 발전의 기초를 마련했고, 클라이언트와 서버 간의 간단한 통신 방식이 자리를 잡았다는 점에서 의미가 있습니다.
2. HTTP/1.0: 기능이 처음으로 확장되다
1996년 5월, HTTP/1.0 (에이치티티피 일점영) 버전이 발표되었습니다.
HTTP/0.9 (에이치티티피 영점구)에 비해 내용이 훨씬 풍부해졌고, 인터넷 발전에 중요한 변화들을 가져왔습니다.
2.1 주요 변경 사항 소개
콘텐츠 형식의 다양화: HTTP/1.0 (에이치티티피 일점영)부터는 어떤 형식이든 보낼 수 있게 됐습니다.
덕분에 인터넷은 단순 텍스트 전송을 넘어 이미지, 영상, 바이너리 파일 같은 다양한 데이터를 주고받을 수 있게 되었고, 이게 바로 인터넷이 다채롭게 발전하는 데 튼튼한 기반이 된 것입니다.
풍부해진 상호작용 명령어: GET (겟) 명령어 외에도 POST (포스트) 명령어와 HEAD (헤드) 명령어가 도입되었습니다.
POST (포스트) 명령어는 주로 사용자 회원가입이나 로그인 시 정보를 제출하는 것처럼 서버에 데이터를 보낼 때 사용됩니다.
HEAD (헤드) 명령어는 실제 자원 내용은 받지 않고, 해당 자원의 정보(메타 정보)만 얻어올 때 주로 쓰입니다.
이런 명령어들이 추가되면서 브라우저와 서버 간의 상호작용 방식이 훨씬 다양해졌습니다.
요청 및 응답 형식의 변화: 매 통신마다 데이터 부분 외에도, 요청의 출처, 클라이언트 종류, 받아들일 수 있는 데이터 형식 같은 메타데이터를 설명하는 헤더 정보(HTTP header)를 반드시 포함해야 했습니다.
추가로 상태 코드(status code), 다중 문자 집합(multi-charset) 지원, 다중 부분 전송(multi-part type), 인증, 캐시, 콘텐츠 인코딩 같은 기능들이 더해졌습니다.
상태 코드는 서버가 요청을 처리한 결과를 나타내는데, 예를 들어 200은 요청 성공, 404는 자원을 찾을 수 없음을 의미합니다.
다중 문자 집합 지원 덕분에 인터넷에서 여러 언어의 콘텐츠가 제대로 표시될 수 있게 되었습니다.
캐시 기능은 반복적인 요청을 줄여 접속 속도를 향상시킬 수 있습니다.
2.2 요청 형식

GET / HTTP/1.0
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5)
Accept: */*HTTP/0.9 (에이치티티피 영점구) 버전에 비해 1.0 버전의 요청 형식은 눈에 띄게 달라졌습니다.
첫 줄은 요청 명령어이고, 끝에는 반드시 프로토콜 버전(HTTP/1.0)을 추가해야 했습니다.
그 아래로는 클라이언트의 상황을 설명하는 여러 줄의 헤더 정보가 이어집니다.User-Agent (유저 에이전트) 필드는 클라이언트의 종류와 버전을 나타내고, Accept (억셉트) 필드는 클라이언트가 받아들일 수 있는 데이터 형식을 선언합니다.
2.3 응답 형식
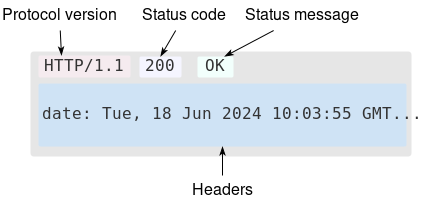
HTTP/1.0 200 OK
Content-Type: text/plain
Content-Length: 137582
Expires: Thu, 05 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 5 August 1996 15:55:28 GMT
Server: Apache 0.84
<html>
<body>Hello World</body>
</html>서버의 응답 형식은 "헤더 정보 + 빈 줄(\r\n) + 데이터"로 구성됩니다.
여기서 첫 줄은 "프로토콜 버전 + 상태 코드 + 상태 설명"입니다.
상태 코드 200은 요청이 성공했음을 나타내고, OK는 상태 설명입니다.Content-Type (콘텐츠 타입) 필드는 데이터의 유형을, Content-Length (콘텐츠 렝스) 필드는 데이터의 길이를 나타냅니다.Expires (익스파이어스) 필드는 리소스의 만료 시간을 지정하고, Last-Modified (라스트 모디파이드) 필드는 리소스의 마지막 수정 시간을, Server (서버) 필드는 서버의 종류와 버전을 알려줍니다.
2.4 Content-Type (콘텐츠 타입) 필드
HTTP/1.0 (에이치티티피 일점영) 버전에서는 헤더 정보가 반드시 ASCII (아스키) 코드여야 했지만, 그 뒤에 오는 데이터는 어떤 형식이든 가능했습니다.
그래서 서버가 응답할 때, Content-Type (콘텐츠 타입) 필드를 통해 클라이언트에게 데이터의 형식을 알려줘야 했습니다.Content-Type (콘텐츠 타입) 필드의 일반적인 값들은 다음과 같은데요.
텍스트 유형: text/plain (일반 텍스트), text/html (HTML 문서), text/css (CSS 스타일시트).
이미지 유형: image/jpeg (JPEG 이미지), image/png (PNG 이미지), image/svg+xml (SVG 벡터 그래픽).
오디오 및 비디오 유형: audio/mp4 (MP4 오디오), video/mp4 (MP4 비디오).
애플리케이션 유형: application/javascript (자바스크립트 스크립트), application/pdf (PDF 문서), application/zip (ZIP 압축 파일), application/atom+xml (Atom XML 문서).
이런 데이터 유형들을 통틀어 MIME (마임) 타입이라고 부릅니다.
각 값은 주 유형(primary type)과 부 유형(secondary type)을 포함하며, 슬래시(/)로 구분됩니다.
미리 정의된 유형 외에도, 제조사들은 사용자 정의 유형을 만들 수도 있습니다.
예를 들어, application/vnd.debian.binary-package는 전송되는 데이터가 데비안(Debian) 시스템의 바이너리 데이터 패키지임을 나타냅니다.
MIME (마임) 타입은 세미콜론을 사용해 끝에 매개변수를 추가할 수도 있습니다.
예를 들어, Content-Type: text/html; charset=utf-8 (콘텐츠 타입: 텍스트/에이치티엠엘; 문자셋=유티에프-팔)은 전송되는 데이터가 웹 페이지이고 인코딩이 UTF-8 (유티에프 팔)임을 나타냅니다.
클라이언트가 요청할 때는 Accept (억셉트) 필드를 사용해 자신이 받아들일 수 있는 데이터 형식을 선언할 수 있는데, 예를 들어 Accept: */*는 클라이언트가 어떤 형식의 데이터든 받아들일 수 있다는 뜻입니다.
MIME (마임) 타입은 HTTP (에이치티티피) 프로토콜뿐만 아니라 다른 분야에서도 널리 사용됩니다.
예를 들어, HTML (에이치티엠엘) 웹 페이지에서는 <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> 또는 <meta charset="utf-8" />을 통해 페이지의 인코딩과 콘텐츠 유형을 지정할 수 있습니다.
2.5 Content-Encoding (콘텐츠 인코딩) 필드
전송되는 데이터는 어떤 형식이든 가능했기 때문에, 전송 효율을 높이기 위해 데이터를 보내기 전에 압축할 수 있었습니다.Content-Encoding (콘텐츠 인코딩) 필드는 데이터의 압축 방식을 나타내는 데 사용됩니다.
일반적인 값으로는 gzip (지집), compress (컴프레스), deflate (디플레이트)가 있습니다.
클라이언트가 요청할 때는 Accept-Encoding (억셉트 인코딩) 필드를 사용해 자신이 받아들일 수 있는 압축 방식을 나타냅니다, 예를 들어 Accept-Encoding: gzip, deflate (억셉트 인코딩: 지집, 디플레이트)처럼 말입니다.
2.6 단점
HTTP/1.0 (에이치티티피 일점영) 버전의 주된 단점은 각 TCP (티시피) 연결이 단 하나의 요청만 보낼 수 있다는 점이었습니다.
데이터가 전송된 후에는 연결이 닫혔고, 다른 자원을 요청하려면 새로운 연결을 다시 맺어야 했습니다.
새로운 TCP (티시피) 연결을 맺는 비용은 꽤 높은 편인데요, 클라이언트와 서버가 세 번의 확인 과정(3-way handshake)을 거쳐야 하고 초기 전송 속도도 느리기(slow start) 때문입니다.
이로 인해 HTTP 1.0 (에이치티티피 일점영) 버전의 성능은 좋지 않았습니다.
웹 페이지에 외부 자원들이 점점 더 많이 로드되면서 이 문제는 더욱 두드러졌습니다.
이 문제를 해결하기 위해, 일부 브라우저들은 요청에 비표준적인 Connection (커넥션) 필드를 사용했습니다.
Connection: keep-alive (커넥션: 킵얼라이브)
이 필드는 서버에게 TCP (티시피) 연결을 닫지 말 것을 요구하여 다른 요청들이 재사용될 수 있도록 하는 것입니다.
만약 서버도 이 필드로 응답한다면, 클라이언트나 서버가 능동적으로 연결을 닫을 때까지 재사용 가능한 TCP (티시피) 연결이 맺어질 수 있었습니다.
하지만 이것은 표준 필드가 아니었고, 구현 방식에 따라 동작이 다를 수 있어서 근본적인 해결책은 아니었습니다.
3. HTTP/1.1: 널리 사용되는 클래식 버전
1997년 1월, HTTP/1.1 (에이치티티피 일점일) 버전이 발표되었는데, 이는 1.0 버전보다 불과 반년 뒤였습니다.
이 버전은 HTTP (에이치티티피) 프로토콜을 더욱 개선했고, 오늘날까지도 널리 사용되는 버전이 되었습니다.
3.1 지속적 연결 (Persistent Connection)
HTTP/1.1 (에이치티티피 일점일) 버전의 가장 큰 변화는 바로 '지속적 연결(persistent connection)'이 도입된 점입니다.
즉, 기본적으로 TCP (티시피) 연결을 닫지 않고 여러 요청에 재활용할 수 있게 된 것인데요.
굳이 Connection: keep-alive (커넥션 킵얼라이브) 라고 선언할 필요가 없어졌습니다.
클라이언트와 서버는 상대방이 한동안 아무런 활동이 없다고 판단되면 능동적으로 연결을 닫을 수 있습니다.
하지만 표준적인 방식은 클라이언트가 마지막 요청에 Connection: close (커넥션 클로즈)를 보내 명시적으로 서버에게 TCP (티시피) 연결을 닫도록 요청하는 것입니다.
현재 대부분의 브라우저는 동일한 도메인에 대해 6개의 지속적 연결을 설정하도록 허용하며, 이는 HTTP (에이치티티피) 프로토콜의 효율성을 크게 향상시켰습니다.
3.2 파이프라이닝 (Pipelining)
HTTP/1.1 (에이치티티피 일점일) 버전은 '파이프라이닝(pipelining)'이라는 기술도 도입했습니다.
동일한 TCP (티시피) 연결 내에서 클라이언트는 여러 요청을 동시에 보낼 수 있게 된 것인데요.
예를 들어, 클라이언트가 두 개의 자원을 요청해야 한다면, 이전 방식은 동일 TCP (티시피) 연결에서 먼저 요청 A를 보내고, 서버의 응답을 기다린 다음, 응답을 받은 후에 요청 B를 보냈습니다.
파이프라이닝 기술을 사용하면 브라우저가 요청 A와 요청 B를 동시에 보낼 수 있게 됩니다.
비록 서버는 여전히 요청 A에 먼저 순서대로 응답하고, 완료된 후에 요청 B에 응답하지만, 이 방식은 HTTP (에이치티티피) 프로토콜의 효율을 한층 더 높였습니다.
3.3 Content-Length (콘텐츠 렝스) 필드
HTTP/1.1 (에이치티티피 일점일) 버전에서는 하나의 TCP (티시피) 연결로 여러 응답을 전송할 수 있습니다.
따라서 어떤 데이터 패킷이 어느 응답에 속하는지를 구분할 수 있는 방법이 필요했습니다.Content-Length (콘텐츠 렝스) 필드의 역할은 바로 이번 응답에 포함된 데이터의 길이를 알려주는 것입니다.
예를 들면 다음과 같습니다.
Content-Length: 3495 (콘텐츠 렝스: 3495)
이 한 줄의 코드는 브라우저에게 이번 응답의 길이가 3495 바이트이고, 이 이후의 바이트들은 다음 응답에 속한다는 것을 알려줍니다.
1.0 버전에서는 Content-Length (콘텐츠 렝스) 필드가 필수는 아니었습니다.
왜냐하면 서버가 TCP (티시피) 연결을 닫는 것을 감지하면 브라우저는 모든 데이터 패킷을 다 받았다는 것을 알 수 있었기 때문입니다.
1.1 버전에서는 TCP (티시피) 연결을 재사용할 수 있기 때문에, 서로 다른 응답들을 구분하기 위해 데이터 길이를 명확히 할 필요가 생겼습니다.
3.4 청크 분할 전송 인코딩 (Chunked Transfer Encoding)
Content-Length (콘텐츠 렝스) 필드를 사용하려면 서버가 응답을 보내기 전에 응답 데이터의 길이를 미리 알고 있어야 한다는 전제 조건이 있습니다.
시간이 오래 걸리는 동적 작업의 경우, 이는 서버가 모든 작업이 끝날 때까지 기다린 후에야 데이터를 보낼 수 있다는 것을 의미하며, 결과적으로 효율이 낮아집니다.
이 문제를 해결하기 위해 HTTP/1.1 (에이치티티피 일점일) 버전은 Content-Length (콘텐츠 렝스) 필드를 사용하지 않고, 대신 "청크 분할 전송 인코딩(chunked transfer encoding)"을 사용할 수 있도록 규정했습니다.
요청이나 응답 헤더에 Transfer-Encoding (트랜스퍼 인코딩) 필드가 있다면, 이는 응답이 정해지지 않은 수의 데이터 덩어리(chunk)로 구성될 것임을 나타냅니다.
예를 들면 다음과 같습니다.
Transfer-Encoding: chunked (트랜스퍼 인코딩: 청크드)
비어있지 않은 각 데이터 덩어리 앞에는 해당 덩어리의 길이를 나타내는 16진수 값이 옵니다.
마지막으로 크기가 0인 덩어리는 이 응답의 데이터가 완전히 전송되었음을 나타냅니다.
다음은 그 예시입니다.
HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked
25
This is the data in the first chunk
1C
and this is the second one
3
con
8
sequence
0이 방법은 서버가 데이터가 생성되는 대로 바로 전송할 수 있게 해주어, "버퍼 모드"를 "스트림 모드"로 대체함으로써 데이터 전송 효율을 향상시킵니다.
3.5 기타 기능들
HTTP/1.1 (에이치티티피 일점일) 버전은 PUT (풋, 자원 업데이트에 사용), PATCH (패치, 자원 부분 업데이트에 사용), HEAD (헤드, GET (겟)과 유사하지만 헤더 정보만 반환하고 자원 내용은 반환하지 않음), OPTIONS (옵션스, 서버가 지원하는 요청 메서드 등의 정보를 얻는 데 사용), DELETE (딜리트, 자원 삭제에 사용)와 같이 많은 동사 메서드(verb methods)를 추가했습니다.
또한, 클라이언트 측 요청 헤더에는 서버의 도메인 이름을 지정하는 데 사용되는 Host (호스트) 필드가 추가되었습니다.
예를 들면 다음과 같습니다.
Host: www.example.com (호스트: 더블유더블유더블유쩜이그잼플쩜컴)
Host (호스트) 필드 덕분에 동일한 서버에 있는 다른 웹사이트로 요청을 보낼 수 있게 되었고, 이는 가상 호스트(virtual hosts)의 등장 기반을 마련했습니다.Host (호스트) 필드를 통해 서버는 서로 다른 도메인 이름에 따라 다른 서비스를 제공할 수 있게 되어, 자원 공유와 분리가 가능해졌습니다.
3.6 단점
HTTP/1.1 (에이치티티피 일점일) 버전은 TCP (티시피) 연결의 재사용을 허용했지만, 동일한 TCP (티시피) 연결 내에서는 모든 데이터 통신이 순차적으로 이루어졌습니다.
서버는 하나의 응답을 완료한 후에야 다음 응답을 처리했습니다.
만약 이전 응답 처리가 엄청 느리면, 뒤이은 많은 요청들이 줄줄이 대기타는 상황이 발생하는데요.
이걸 'Head-of-line blocking (헤드 오브 라인 블로킹)'이라고 부릅니다.
이 문제를 피하기 위해 현재는 두 가지 방법밖에 없습니다.
하나는 요청 수를 줄이는 것이고, 다른 하나는 동시에 여러 개의 지속적 연결을 여는 것입니다.
이로 인해 스크립트와 스타일시트 병합, CSS (씨에스에스) 코드에 이미지 삽입, 도메인 샤딩(domain sharding)과 같은 많은 웹 페이지 최적화 기술들이 등장하게 되었습니다.
하지만 만약 HTTP (에이치티티피) 프로토콜이 더 잘 설계되었다면, 이런 추가적인 노력들은 피할 수 있었을 것입니다.
4. SPDY (스피디) 프로토콜: HTTP/2 (에이치티티피 투)의 선구자
2009년, Google (구글)은 자체 개발한 SPDY (스피디) 프로토콜을 공개했는데요, 주된 목표는 HTTP/1.1 (에이치티티피 일점일)의 낮은 효율성 문제를 해결하는 것이었습니다.
Chrome (크롬) 브라우저에서 실행 가능성이 입증된 후, SPDY (스피디) 프로토콜은 HTTP/2 (에이치티티피 투)의 기초로 사용되었고, 주요 특징들이 HTTP/2 (에이치티티피 투)에 계승되었습니다.
SPDY (스피디) 프로토콜은 헤더 정보 압축 및 다중화(multiplexing)와 같은 HTTP (에이치티티피) 프로토콜 최적화를 통해 데이터 전송 효율을 개선했고, HTTP/2 (에이치티티피 투) 개발에 귀중한 경험과 기술적 토대를 제공했습니다.
5. HTTP/2: 효율적인 차세대 프로토콜
2015년에 HTTP/2 (에이치티티피 투)가 발표되었습니다.
HTTP/2.0 (에이치티티피 이쩜영)이라고 부르지 않는 이유는 표준 위원회가 더 이상 하위 버전을 출시할 계획이 없기 때문입니다.
다음 새 버전은 HTTP/3 (에이치티티피 쓰리)가 될 예정인데요.
HTTP/2 (에이치티티피 투)는 HTTP (에이치티티피) 프로토콜 발전 역사에서 매우 중요한 의미를 가지며, 일련의 주목할 만한 개선 사항들을 가져왔습니다.
5.1 바이너리 프로토콜 (Binary Protocol)
HTTP/1.1 (에이치티티피 일점일) 버전의 헤더 정보는 텍스트(ASCII (아스키) 인코딩)였고, 데이터 본문은 텍스트 또는 바이너리일 수 있었습니다.
하지만 HTTP/2 (에이치티티피 투)는 완전히 바이너리 프로토콜입니다.
헤더 정보와 데이터 본문 모두 바이너리이며, 이들을 통틀어 "프레임(frame)"이라고 부르는데, 헤더 프레임과 데이터 프레임이 있습니다.
바이너리 프로토콜의 장점은 추가적인 프레임을 정의할 수 있다는 것입니다.
HTTP/2 (에이치티티피 투)는 거의 10가지에 가까운 프레임을 정의했으며, 이는 미래의 고급 응용 프로그램들을 위한 좋은 기반을 마련했습니다.
만약 이런 기능들을 텍스트를 사용해 구현했다면 데이터 파싱이 매우 번거로웠겠지만, 바이너리 파싱은 훨씬 편리합니다.
바이너리 프로토콜은 데이터를 더 효율적으로 전송하고 처리할 수 있어 프로토콜의 성능과 유연성을 향상시킵니다.
5.2 다중화 (Multiplexing)
HTTP/2 (에이치티티피 투)는 TCP (티시피) 연결을 재사용합니다.
하나의 연결에서 클라이언트와 브라우저(서버를 의미하는 것으로 보입니다) 모두 여러 요청이나 응답을 동시에 보낼 수 있으며, 이들이 순서대로 일대일로 대응할 필요가 없어 'Head-of-line blocking (헤드 오브 라인 블로킹)'을 피할 수 있습니다.
예를 들어, 하나의 TCP (티시피) 연결에서 서버가 요청 A와 요청 B를 동시에 받았습니다.
그래서 먼저 요청 A에 응답하기 시작했는데, 처리 과정이 매우 오래 걸린다는 것을 발견하면, 이미 처리된 요청 A의 일부를 먼저 보내고, 그 다음 요청 B에 응답합니다.
요청 B 처리가 완료된 후, 나머지 요청 A 부분을 마저 보냅니다.
이러한 양방향 실시간 통신을 다중화(multiplexing)라고 부릅니다.
다중화 기술 덕분에 HTTP/2 (에이치티티피 투)는 동일한 연결에서 여러 요청과 응답을 동시에 처리할 수 있게 되어 전송 효율을 크게 향상시켰습니다.
5.3 데이터 스트림 (Data Streams)
HTTP/2 (에이치티티피 투)에서는 데이터 패킷들이 순서 없이 전송되기 때문에, 동일 연결 내의 연속된 데이터 패킷들이 서로 다른 응답에 속할 수 있습니다.
따라서 데이터 패킷에 표시를 해서 어떤 응답에 속하는지를 나타낼 필요가 있습니다.
HTTP/2 (에이치티티피 투)는 각 요청 또는 응답의 모든 데이터 패킷을 데이터 스트림(data stream)이라고 부릅니다.
각 데이터 스트림에는 고유한 번호가 있습니다.
데이터 패킷을 보낼 때는 반드시 데이터 스트림 ID를 표시하여 어떤 데이터 스트림에 속하는지를 구분해야 합니다.
또한, 클라이언트가 보내는 데이터 스트림은 홀수 번호의 ID를 가지고, 서버가 보내는 데이터 스트림은 짝수 번호의 ID를 가지도록 규정되어 있습니다.
데이터 스트림이 중간에 전송 중일 때, 클라이언트와 서버 모두 신호(RST_STREAM (알에스티 스트림) 프레임)를 보내 이 데이터 스트림을 취소할 수 있습니다.
HTTP/1.1 (에이치티티피 일점일) 버전에서는 데이터 스트림을 취소하는 유일한 방법이 TCP (티시피) 연결을 닫는 것이었습니다.
하지만 HTTP/2 (에이치티티피 투)에서는 TCP (티시피) 연결이 계속 열려 있고 다른 요청에 사용될 수 있도록 보장하면서 특정 요청을 취소할 수 있습니다.
클라이언트는 데이터 스트림의 우선순위를 지정할 수도 있습니다.
우선순위가 높을수록 서버는 더 빨리 응답할 것입니다.
데이터 스트림이라는 개념과 관련 메커니즘을 통해 HTTP/2 (에이치티티피 투)는 더 유연하고 효율적인 데이터 전송 및 관리를 실현합니다.
5.4 헤더 압축 (Header Compression)
HTTP (에이치티티피) 프로토콜은 상태를 저장하지 않는(stateless) 프로토콜이라서, 모든 정보가 각 요청에 첨부되어야 합니다.
그래서 요청에 포함된 많은 필드들, 예를 들어 Cookie (쿠키)나 User-Agent (유저 에이전트) 같은 것들이 반복됩니다.
동일한 내용이 각 요청에 첨부되어야 하므로 많은 대역폭을 낭비하고 속도에도 영향을 미칩니다.
HTTP/2 (에이치티티피 투)는 헤더 압축 메커니즘을 도입하여 이 문제를 최적화했습니다.
한편으로는, 헤더 정보를 전송하기 전에 gzip (지집)이나 compress (컴프레스)를 사용해 압축합니다.
다른 한편으로는, 클라이언트와 서버 모두 헤더 정보 테이블을 유지합니다.
모든 필드는 이 테이블에 저장되고 인덱스 번호가 생성됩니다.
앞으로는 동일한 필드를 다시 보내지 않고 인덱스 번호만 보내 속도를 향상시킵니다.
헤더 압축 메커니즘은 데이터 전송량을 효과적으로 줄이고 전송 효율을 높입니다.
5.5 서버 푸시 (Server Push)
HTTP/2 (에이치티티피 투)는 서버가 요청 없이도 클라이언트에게 능동적으로 자원을 보낼 수 있도록 허용하는데, 이를 서버 푸시(server push)라고 합니다.
일반적인 시나리오는 클라이언트가 많은 정적 자원을 포함하는 웹 페이지를 요청하는 경우입니다.
보통 상황이라면 클라이언트는 웹 페이지를 받고, HTML (에이치티엠엘) 소스 코드를 분석하여 정적 자원들을 발견한 다음, 그 정적 자원들에 대한 요청을 보내야 합니다.
하지만 서버는 클라이언트가 웹 페이지를 요청한 후 정적 자원들을 요청할 가능성이 높다고 예상할 수 있으므로, 웹 페이지와 함께 이러한 정적 자원들을 클라이언트에게 능동적으로 보냅니다.
서버 푸시 기술은 클라이언트 요청 횟수를 줄이고 사용자 경험을 향상시킵니다.
HTTP (에이치티티피) 프로토콜의 발전사는 끊임없는 진화와 최적화의 과정 그 자체였습니다.
처음의 단순했던 HTTP/0.9 (에이치티티피 영점구)에서부터 기능이 풍부해진 HTTP/1.1 (에이치티티피 일점일), 그리고 효율적인 HTTP/2 (에이치티티피 투)에 이르기까지, 각 버전은 이전 버전의 문제점들을 해결하고 성능과 기능을 강화해왔습니다.
기술이 계속 발전함에 따라, 미래의 HTTP/3 (에이치티티피 쓰리) 역시 인터넷 통신 기술의 발전을 계속 이끌어갈 것이기에 기대해볼 만합니다.
'Javascript' 카테고리의 다른 글
| Base64 (베이스64) 인코딩 완벽 정복: 당신이 알아야 할 모든 것 (1) | 2025.05.17 |
|---|---|
| 웹 페이지 로딩 속도 개선의 핵심! HTTP 캐싱: 강력한 캐시와 협상 캐시 완전 정복 (0) | 2025.05.17 |
| 자바스크립트 메타프로그래밍 파헤치기: 리플렉션과 심볼, 너희 정체가 뭐니? (0) | 2025.05.07 |
| HTML <script> 태그의 async와 defer, 확실히 알고 쓰시나요? (0) | 2025.05.06 |
| 철벽 API 디자인을 위한 18가지 필수 규칙 (0) | 2025.05.06 |